
Photo by Igor Omilaev on Unsplash
Think about this situation before you get started.
Imagine your research agent finds a credentials file it wasn't supposed to access. It's just doing its job, gathering context. It hands this information to your coding agent, which uses it to authenticate an API call and make a commit. Your operations agent logs the commit, but not the credential access, because that happened in a different process with a separate audit trail. By the time you notice something is off, three things have happened that you didn't approve, can't fully track, and can't easily fix.
There's no hacker involved. No strange exploit. It's just agents doing what they were built to do, using the authority you gave them, often without clear limits.
Most builders aren't thinking about this kind of problem. The new hardware coming out this fall makes it even more likely.
At Computex 2026, Jensen Huang introduced RTX Spark. It has a 20-core Grace CPU, a Blackwell GPU, 128GB of unified memory, and a petaflop of AI compute in a laptop.1 The CPU and GPU use the same memory pool, so there's no bottleneck moving data between them. A 70B parameter model can run locally with less than 500ms latency. Over three years or more, the hardware pays for itself, while running similar speeds in the cloud costs money every time you use it.2
For agents that often make tool calls — like routing, retrieval, classification, or reasoning — this changes everything.
Now, the intelligence is on your machine. The risks are, too.
We've seen this before
Before personal computers, only places like universities and data centers had real computing power. You had to borrow time on someone else's machine. Then computers became personal, and what had belonged to big institutions became available to everyone.
Cloud AI is similar to that old setup. The intelligence is somewhere else. You make API calls, pay per token, and a provider sits between what you want and what happens.
Local AI removes that middle layer, which is exactly why it changes the risks.
Cloud agents have built-in controls. API rate limits stop runaway actions, per-token costs slow things down, and the provider's safety layer shields your agent from outside threats. Local inference doesn't have any of that. It's just your agents, your hardware, and all the authority you've given them.
The question nobody is asking
The main question in the agent ecosystem is: what can these agents do?
Can they write code? Browse the web? Send email? Execute shell commands? Make purchases? Yes, yes, yes, yes, and increasingly yes.
But hardly anyone is asking: who gave them permission?
If your agent can send email, should it send this particular message? If it can spend money, how much should it spend, who gets paid, and for what? If it can access files, which files are allowed? If several agents work together and disagree, which one makes the final call?
These aren't rare edge cases. They're the normal situation for most agent deployments. Systems are built for capability, and governance is often added later or not at all.
Over centuries, human organizations learned that capability without governance leads to chaos. Budgets, permissions, audit trails, escalation paths, and org charts don't exist because we distrust workers. They exist because coordination is difficult, and the impact of mistakes grows with authority. Llama.cpp doesn't come with any of that built-in knowledge.
What treating it like an organization looks like
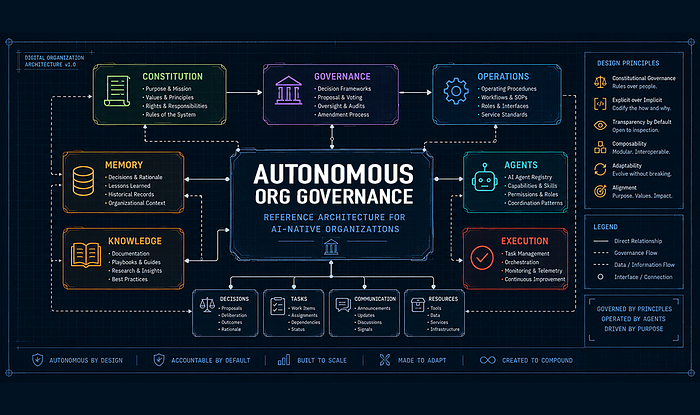
I built a framework around a simple idea: if you're running autonomous agents with real authority, treat them like employees in an organization, not just scripts.
Here's what that looks like: a Research Director role can browse the web and update the knowledge base, but can't send email or run code, and is limited to $50 per month in external API costs. An Engineering Director can read and write code, but can't push to production without human approval. An Operations Director can move files through an approved airlock, but can't access anything outside the sandbox. Every role has clear capabilities, and each has a defined worst-case outcome — a maximum acceptable loss — after which the action must be escalated rather than handled automatically.
The hardest design decision, beyond technical choices, is how agents behave. They should be set up to escalate when they're unsure, not to guess. An agent that stops and asks is more trustworthy than one that just fills in the blanks. Most agent frameworks focus on finishing tasks. This one focuses on knowing when not to act.
NVIDIA is starting to address this at the infrastructure level. Their Agent Toolkit includes NemoClaw, an open-source reference stack for adding security guardrails to local agents.3 That's necessary, but not enough. Infrastructure guardrails cover what the platform can see. Organizational governance covers what you decide — like which roles exist, what they're allowed to do, how authority moves between them, and what happens if something goes wrong. That part is still up to the builder.
The framework is open-source and built as a template. You set your own roles, spending limits, and approved tools and systems. It doesn't need a specific tech stack. Instead, it gives you a structure you can read, change, give to an agent as its charter, and review later.
autonomous-org-governance on GitHub →
Governance before the agents are running
RTX Spark launches this fall. Builders will have local petaflop-class AI before most have really considered what it means to run an autonomous organization on their own hardware, with no middleman, no rate limits, and no outside safety layer.
That's when you need to think about governance: before the agents are running, not after.
This post also appears on Medium.
-
NVIDIA, "Introducing RTX Spark," NVIDIA Newsroom, May 31, 2026. https://nvidianews.nvidia.com/news/nvidia-rtx-spark ↩
-
ChatForest, "RTX Spark: NVIDIA's Local AI Superchip Is Official — What Builders Need to Know," June 2026. https://chatforest.com/builders-log/nvidia-rtx-spark-computex-2026-local-ai-builder-guide/ ↩
-
NVIDIA, "NVIDIA Levels Up Local AI Agents Across RTX PCs and DGX Spark," NVIDIA Blog, June 2026. https://blogs.nvidia.com/blog/rtx-ai-garage-computex-spark-local-agents/ ↩